What happens when you type'google.com'into a browser and press Enter?
4943人浏览 / 0人评论
My most favorite interview question I've come across yet was "You type 'google.com' into a browser address bar and hit , what happens afterwards?"
Someone could talk for days on end trying to answer that with some form of completeness. How deep will they go? Strictly for fun, I'm going to put my answer here. When I was asked this in an actual interview, I rambled on for a good 10 minutes before they stopped me. And then I kept remembering things I forgot to include even after the interview finished.
I'm going to keep this formatted as a wall of text because that's how it felt to answer this question in conversation.
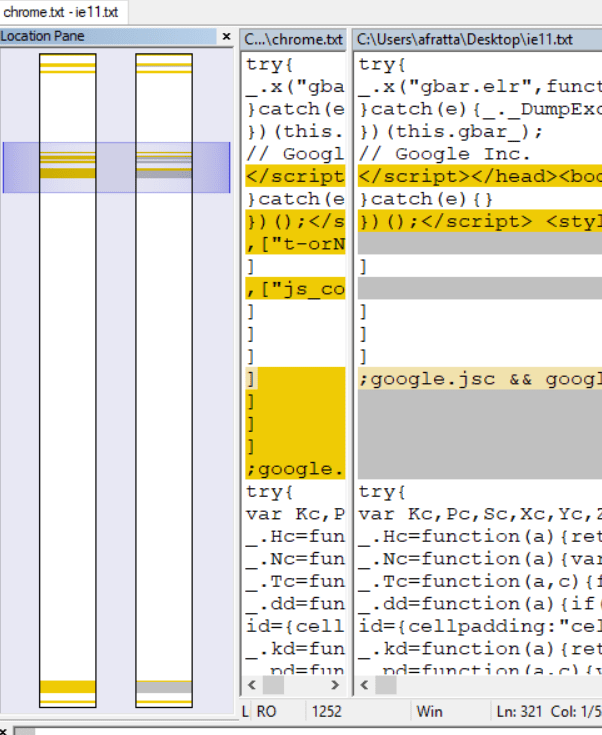 Above is a file comparison of the IE 11 and Chrome responses - both logged out.
Above is a file comparison of the IE 11 and Chrome responses - both logged out.
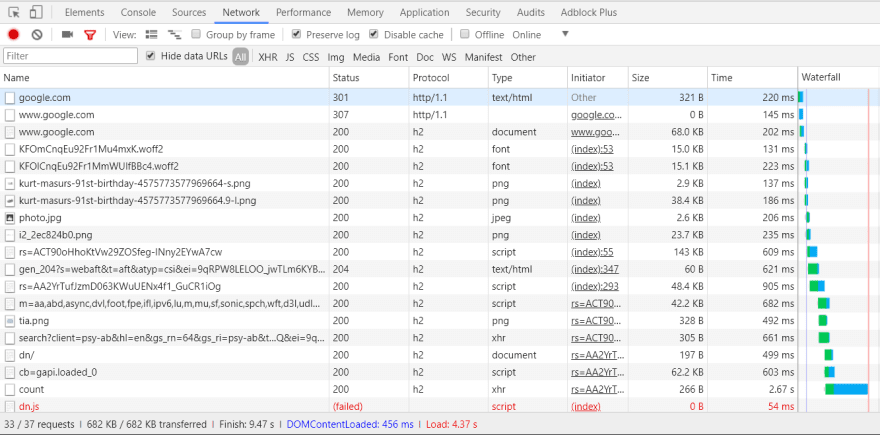
 That pic above is the first screenshot Chrome will give you.
That pic above is the first screenshot Chrome will give you.
So What Happens?
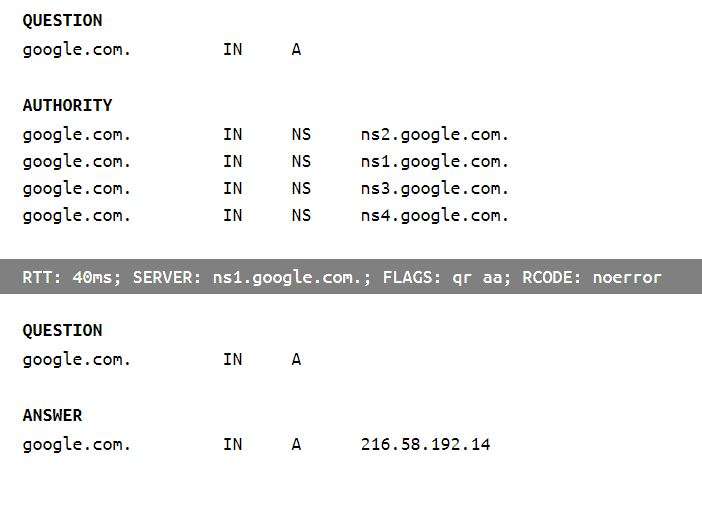
The browser is going to analyze the input. Usually if it has a ".com" it won't think you're typing search terms. And once it decides it must be a URL, it'll check that it has a scheme, if not, it'll add "http://" to the beginning. And since you didn't specify a number of HTTP protocol features, it'll assume defaults, like port 80, GET method and no basic auth. Then it'll create an HTTP request and send that. I'm not confident in my low level networking knowledge but if I was I'd say something about the MAC address, TCP packet transfers, dropped packet handling. But anyway, a "google.com" DNS lookup will happen, and if it's not already cached a DNS service will reply with a list of IP addresses, because "google.com" doesn't just have a single IP address. Browsers will pick the first one by default I believe. Not sure if they're regional or how the list works, but I know it's there. So the HTTP request jumps from node to node until it gets to the IP address of google.com's load balancer. It wouldn't last long, Google would respond that you need to be using HTTPS - assuming with a 301 permanent redirect. So it would go all the way back to your browser, the browser would change the scheme to HTTPS, use the default 443 port and resend. This time the TLS handshake would take place between the load balancer and the browser client. Not 100% on how that works but I know the request would tell Google what protocols it supports (TLS 1.0, 1.1, 1.2) and Google would respond with "Let's use 1.2". Then the request gets sent with TLS encryption. I think the next thing Google would do is put it through web application firewall rules on its load balancer to see if it's a malicious request. When it passes, the secure connection has probably been terminated (because PCI-DSS regulations say you don't need to encrypt internal traffic) and the request would get assigned to a pool in their CDN, and the google-side cached homepage will be returned in an HTTP response. Probably pre-gzipped. Google's response header would be read by the browser, cached according to the response header caching policy, then the body would be un-gzipped. And because it's google it's probably ultra-optimized: minified, likely a lot of pre-rendered content, inlined CSS, JavaScript and images to reduce network requests and the time-to-first-render. But that request will trigger a cascade of other requests, all concurrent because it should be running HTTP/2. While those requests are being made, JavaScript would be parsed, probably not blocking because they used the defer attribute on their tags - or async, I never did read about what those did individually. But the browser has probably already rendered the search box and is working on the toolbar at the top, which is going to take some extra network requests - I probably already have a cookie or maybe local storage with an OAuth token - or maybe I'm using Chrome and it already knows who I am, and that request with auth gets sent to their Google+ API that tells the Google search page application who I am. Another request would be sent to get my avatar image. At this point they've already browser-sniffed to see if I wasn't using Chrome, in which case they would have popped-in a tooltip to tell me that Chrome is awesome and I should be using that instead of anything else. I think it would quiet down at that point. All taking place in a fraction of a second.What is observably different?
Let's lookup the DNS:
- I know I had previously seen google.com coming back with multiple IP addresses, but that doesn't seem to be the case anymore. Seems that they used to use round-robin but don't anymore. This StackOverflow question covers it. I had forgotten it was called round-robin.
- I missed that in TLS they exchange certificates after agreeing on a protocol.
- Networking isn't my strongest arena.
- I missed the host name canonicalization - which was a 301.
- The correction from HTTP to HTTPS is a 307 Internal Redirect.
- It then downloads fonts, the logo images, and my avatar image. Without an API call, which means they shoved my profile information in the page and bundled that with the return - so they're doing actual data retrieval when you hit google.com and not just serving cached assets.
The Response
Above is a file comparison of the IE 11 and Chrome responses - both logged out.
- Not terribly different between IE11 and Chrome. But it means they're user-agent sniffing server-side and not client-side. Could have mentioned this in my answer.
- Unexpectedly, the Chrome response is larger by 22kB. I wonder if it's the search-by-voice feature, which is visibly absent from IE 11. IE11 probably needs polyfills and the Chrome advertisement but it's all obfuscated and I'm not going to torture myself any further.
- Even after I clear my cookies in Chrome, it still sends cookies on first request. It does not do that in IE 11.
That pic above is the first screenshot Chrome will give you.
- There aren't any async or defer attributes on the script tags, just nonce attributes. I'm learning about nonce as of this minute, and it seems to be security related. I guess they want those blocking scripts. I'm sure they fiddled around with/without async/defer at some point and decided against it.
- Note to self: Full response is a mess of mixed JavaScript, CSS, and HTML. They aren't following any rules governing their placement in regards to separation.


